
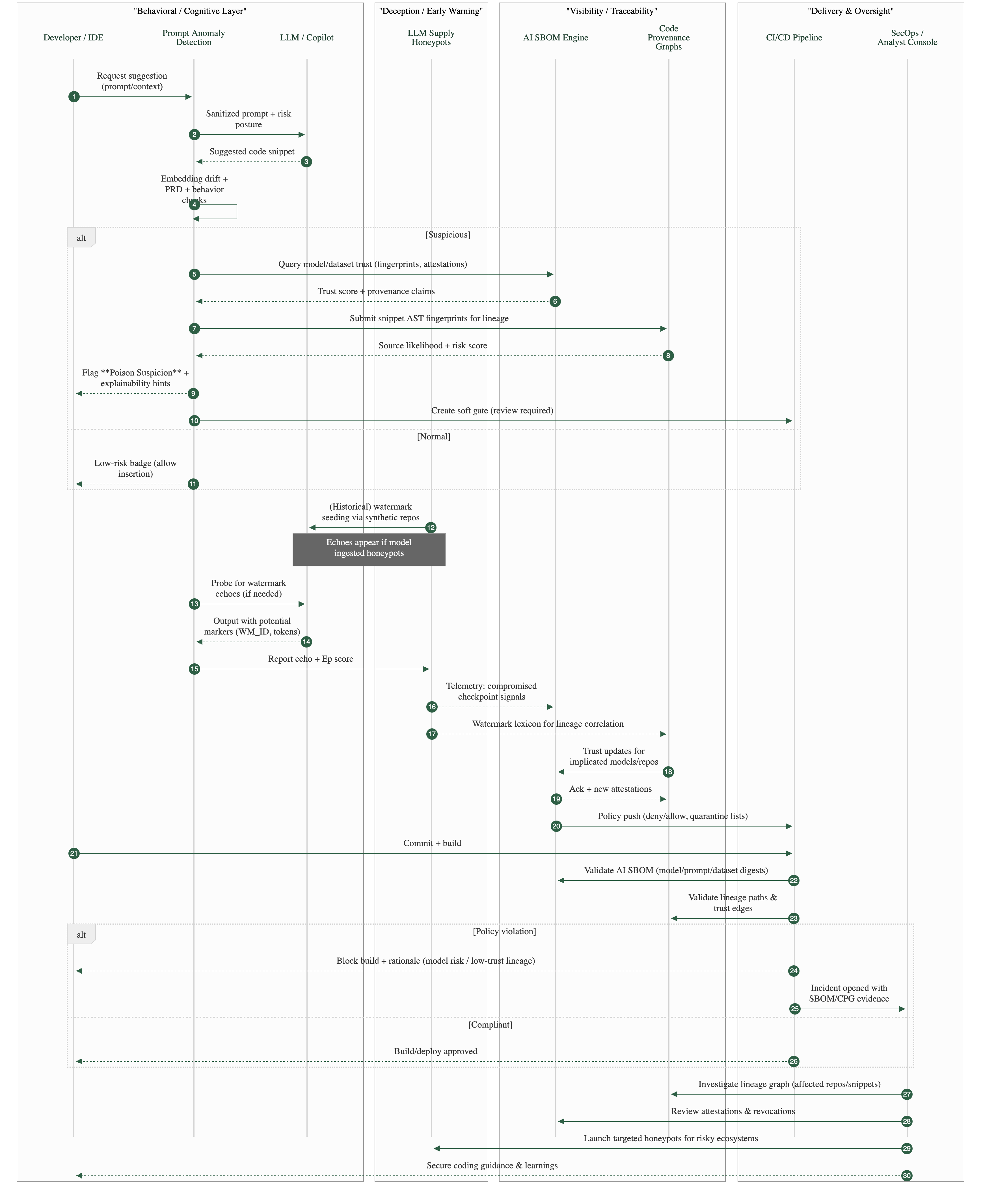
Infiligence recommends DevOps teams must integrate “Prompt Anomaly Detection” directly within developer IDEs. This system analyzes prompt-context and model responses for unusual linguistic or behavioral deviations, which are early signs of data poisoning or targeted LLM manipulation. Developers receive instant alerts when a suggestion seems off-pattern or anomalous.
Linguistic deviations are too vague to operationalize. Developers need concrete anomaly-detection signals for model responses embedded in their IDEs.
Prompt Anomaly Detection correlates semantic drift, syntactic entropy, and behavioral deviation metrics to flag suspicious AI outputs in real time.
Core Components:
4.1 Linguistic Drift Analysis
- Compute the cosine distance between current model response embeddings and historical developer-specific embedding baselines.
- Use thresholds calibrated via z-scores of response embedding distances (e.g., flag if deviation > 2σ from baseline).
4.2 Behavioral Deviation Metrics
- Extract operational signals such as number of API calls, dependency imports, file-write patterns, or system calls suggested by the model.
- Compare to historical “developer-intent profiles” (captured via lightweight telemetry) using anomaly-detection models like Isolation Forest or Autoencoder Reconstruction Error.
4.3 Toxicity & Malicious Intent Classifiers
- Integrate fine-tuned classifiers trained on malicious prompt datasets (e.g., JailbreakBench).
- Classify model outputs into risk buckets: benign / suspicious / exploit-pattern.
4.4 Prompt-Response Correlation Scoring
- Generate a Prompt-Response Delta Score:
PRD = (semantic_similarity(prompt, response) × response_perplexity)^−1
- High PRD = response diverges semantically from intent while exhibiting high complexity but a strong anomaly signal.
4.5 IDE Integration & Alerting
- Embed PAD as a VS Code / JetBrains plugin.
- Display real-time risk badges (“Normal”, “Deviant”, “Poison Suspicion”).
- Optionally block commits until developer review.
Outcome:
- PAD transforms the IDE into a live cognitive firewall, detecting “prompt-level poisoning” and behavioral anomalies before malicious suggestions enter version control.
- Prompt Anomaly Detection closes the cognitive-defense loop.
- It monitors developer–model interactions for deviations and cross-checks them against both SBOM-verified model fingerprints and Honeypot telemetry.
- If PAD identifies high-risk semantic drift consistent with known poisoned patterns, it triggers automated re-scoring within the Code Provenance Graph and issues an SBOM trust alert, linking behavioral anomalies back to their generative origins.
Turning AI Automation Into Secure Innovation
The goal is not to restrict AI adoption, it’s to make it resilient. By combining visibility (AI SBOMs), deception (Honeypots), traceability (Provenance Graphs), and behavioral intelligence (Prompt Anomaly Detection), Infiligence offers a proactive blueprint for enterprises to embrace AI while staying secure.
The four modules form a closed-loop defense fabric:
- Visibility (AI SBOMs)
- Deception (LLM Honeypots)
- Traceability (Provenance Graphs)
- Behavioral Intelligence (PAD)
Data Flow and Feedback Loop
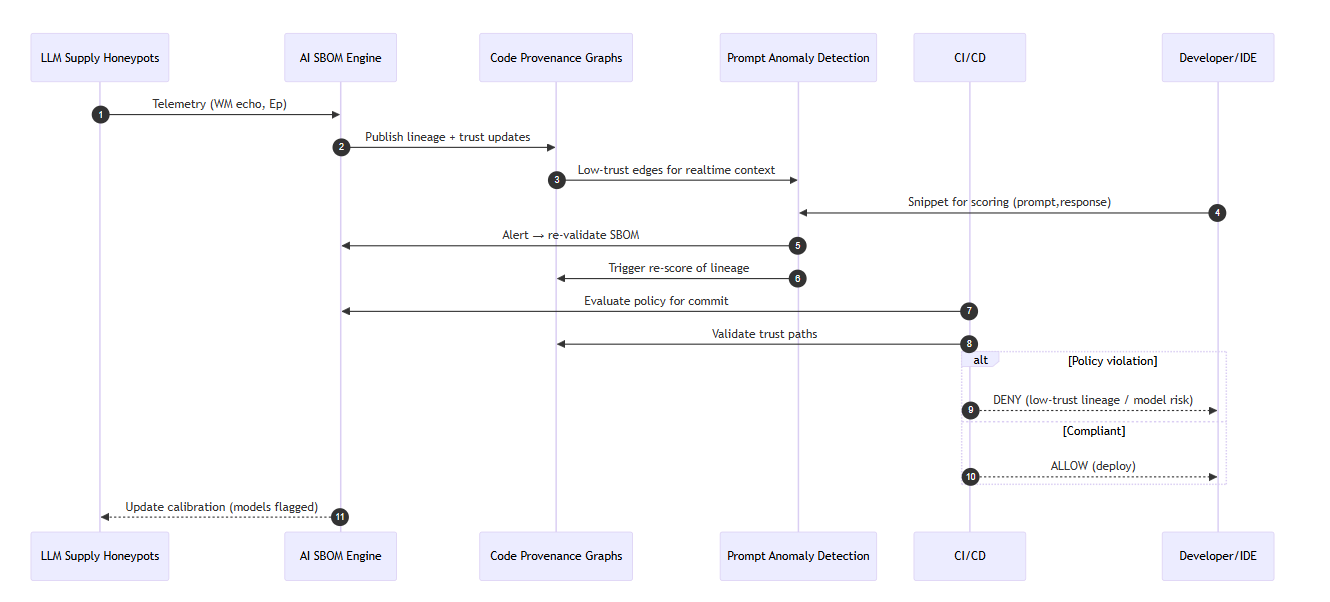
The four defense modules — AI SBOMs, LLLM Supply Honeypots, Code Provenance Graphs, and Prompt Anomaly Detection (PAD) — operate not as isolated tools but as a synchronized feedback system. Each generates telemetry that informs and strengthens the others, forming a closed-loop cognitive defense fabric across the AI-driven DevSecOps pipeline.
1. Honeypots → SBOMs: Feeding Early Warning into Trust Registries
LLM Supply Honeypots act as the deception and detection layer. When a model reproduces watermarked markers or unique code signatures from synthetic repositories, that signal, captured as telemetry and Echo Probability (Ep), is transmitted to the AI SBOM Engine.
The SBOM system logs the compromised model fingerprints and poisoned dataset indicators, instantly updating the enterprise’s Model Trust Registry. This gives downstream systems the ability to recognize contaminated AI sources before they influence production code.
2. SBOMs → Provenance Graphs: Enriching Lineage and Trust Context
The updated SBOM manifests feed directly into the Code Provenance Graphs, where verified lineage data enhances each node’s trust score.
By linking every AI-generated artifact to its verified model, dataset, and prompt hash, the Provenance Graph transforms abstract provenance into a living trust topology. This helps security teams understand not only where code originated but how much confidence each lineage path deserves.
3. Provenance Graphs → PAD: Turning Lineage into Real-Time Defense
Low-trust or ambiguous edges within the Provenance Graph are broadcast to Prompt Anomaly Detection (PAD) within developer IDEs.
PAD uses this context to fine-tune its behavioral baselines, flagging AI-suggested code that traces back to models or datasets with degraded trust. Developers receive real-time alerts when suggestions deviate from verified lineage, effectively embedding supply-chain intelligence into their day-to-day coding workflow.
4. PAD → SBOMs + Graphs: Closing the Cognitive Defense Loop
When PAD detects high-risk anomalies such as semantic drift, obfuscated logic, or behavioral outliers, it triggers automated revalidation events.
These events prompt the AI SBOM Engine to recheck the model’s provenance and notify the Provenance Graph to adjust corresponding trust scores.
This feedback loop ensures that even post-deployment anomalies continuously refine the upstream lineage map, converting developer-side intelligence into enterprise-wide resilience.
5. SBOMs ↔ Honeypots: Continuous Feedback and Reinforcement
Finally, the SBOM and Honeypot layers maintain a continuous feedback exchange.
Newly identified compromised models feed honeypot telemetry calibration, while honeypot discoveries update SBOM trust scores. Over time, this creates a symbiotic system that predicts and pre-empts model-level poisoning campaigns, sharpening detection precision with each cycle.
Outcome: The Cognitive Immune System for AI DevSecOps
Together, these interactions create a self-learning defensive mesh where deception, visibility, traceability, and behavioral intelligence converge.
Each feedback loop sharpens the system’s collective awareness, turning every detection event into future immunity.
In essence, the Infiligence architecture doesn’t just monitor trust, it evolves with it, forming a Cognitive Immune System for the AI-powered software supply chain.
Conclusion: From Fattening to Fortification
The next wave of enterprise compromise won’t begin with a phishing email. It will begin with an AI model generating one vulnerable line of code. Infiligence is leading the charge in securing the AI-powered DevSecOps ecosystem by reframing trust as a measurable, monitorable asset. In a world where automation can scale both productivity and deception, Infiligence ensures that intelligence, not trust, becomes your strongest defense.
For a deeper look into our AI DevSecOps research or to join our enterprise Tech Due Diligence assessments, visit us at www.infiligence.com or contact info@infiligence.com.
References / Further reading:
- Wang, H. et al. Models Are Codes: Towards Measuring Malicious Code Poisoning Attacks on Pre-trained Model Hubs. ASE ’24.
- Wang, S., Zhao, Y., Liu, Z., Zou, Q., Wang, H. SoK: Understanding Vulnerabilities in the Large Language Model Supply Chain. arXiv, 2025.
- Wang, H., Guo, S., He, J., Liu, H., Zhang, T., Xiang, T. Model Supply Chain Poisoning: Backdooring Pre-trained Models via Embedding Indistinguishability. arXiv, Jan 2024.
- OWASP GenAI Security Project. LLM03:2025 Supply Chain — LLM supply chains are susceptible to various vulnerabilities… [Online].
- IBM Think Insights. How cyber criminals are compromising AI software supply chains.
- CSET, Georgetown. Cybersecurity Risks of AI-Generated Code. (Report).
Explore the complete Pig Butchering 2.0 series:
Part 1/4 - Pig Butchering 2.0: How Data-Poisoning and Model Grooming Undermine AI-Driven DevSecOps
Part 2/4 - LLM Supply Honeypots
Part 3/4 - LLM Code Provenance Graphs
Part 4/4 - Prompt Anomaly Detection in IDEs
Detailed material for access – GitHub
Co-authored by

Venkatakrishnan Jayakumar is a seasoned cloud and DevOps leader with over two decades of experience transforming enterprise IT—from physical infrastructure deployments to cloud-native, scalable architectures. His expertise spans infrastructure migration, cloud architecture, Kubernetes, and automation, helping organizations accelerate time to market without compromising security or reliability.
Before joining Infiligence, Venkat led the DevOps and Cloud Center of Excellence at Concentrix Catalyst, delivering scalable solutions for global enterprises like Honeywell and Charter. Earlier, he drove large-scale data center migrations at Zurich and engineered modern infrastructure solutions involving blade servers and enterprise storage systems.
At his core, Venkat is passionate about building secure, resilient, and high-performing platforms that empower businesses to innovate with confidence.

Ajitha Ravichandran is an experienced QA engineer with a strong background in automation testing, CI/CD integration, and quality engineering for cloud-native applications. She brings hands-on expertise in designing and implementing robust testing frameworks that ensure secure, scalable, and high-performing enterprise solutions.
At Infiligence, Ajitha focuses on building next-generation platform engineering solutions that unify security, observability, and automation—helping clients achieve faster delivery cycles and stronger operational governance.
Her earlier experience spans cloud migration projects, Kubernetes deployments, and automation frameworks that streamline application lifecycle management across hybrid and multi-cloud ecosystems. Ajitha is passionate about driving engineering excellence and enabling teams to build with confidence in the cloud.

